后缀自动机
WX 讲的太抽象了,不想听。
定义
-
给定一张 DAG,边有边权。称节点为状态,边为转移。
-
有源点 称其为初始状态,有至少一个汇点满足从 走到这个节点经过的边组成的字符串是 串的后缀。
-
所有的从 出发的路径都可以找到对应的 中的字串(连续的),每一个 中的字串都有一个从 出发的路径与之对应。
如果满足上面的条件,而且节点是最少的那么这个图就是一个后缀自动机。
定义 表示字符串 出现在 的字串中最后一个元素的位置,需要注意 可能在 中多次出现,所以 是一个集合。
举个例子,,,那么就有 。
等价类
如果两个字符串 和 满足 那么就称 和 在一个等价类中。注意必须要是相等,而包含关系不算。
等价类有一些性质:
- 如果 属于一个等价类而且 ,那么 一定是 的字串。
- 如果 ,那么一定有 或者 。
- 一个等价类里的字符串的长度是连续的。
性质容易证明,故不再赘述。
对于 SAM 上的一个节点 ,定义 表示从 到所经过的边的数量,换而言之也就是一这个点结尾的左右的子串中最长的一个的长度。
oi-wiki 上有一个显然:所有从 到达状态 经过的转移形成的字符串的 相等。
于是有一个强有力的性质,所有从 到达状态 经过的转移形成的字符串都属于一个等价类。
甚至这个性质的逆命题也是正确的,也就是所有等价类一样的字串的状态都是一样的。
oi-wiki 都不会证,好像要用 迈希尔-尼罗德定理 证明 SAM 是正则的。
考虑对于一个状态 ,定义 表示这个等价类中最短的字符串删除了第一个字母之后做得到的字符串的等价类对应的状态。
为了便于陈述 的性质,定义 。
引理 1
把 设置一条连向 的边,那么得到的图就一定是一个以 为根的外向的树。
证明:
因为 在求解的时候是通过不断删除字符计算的,所以对于任意一个状态一直令 最终都会有 。
因为每一个状态 都只有一个出边,而且最终汇入了 所以这样得到的把边反转的图一定是一棵树。
引理 2
考虑一种新的建树方式:
对于两个状态 ,如果 而且 ,那么我们把 想 连接一条边。
有性质这样用 和 建出的树是一样的。
证明容易理解,结合前面的这个性质:
如果 ,那么一定有 或者 。
操作
SAM 与 SA 不同,它是一个在线的算法,也就是我们可以在字符串 后面动态的添加字符然后更新 SAM。
流程
考虑令 的编号为 ,,。
如果添加的新字符为 ,那么过程如下:
- 令 为添加 之前的 最大的状态,也就是例子的 节点(如果是第一步那么我们令 )。
- 为了可以表示整个字符串,我们必定要新建一个节点 ,显然 。
- 从 开始,依次遍历 ,如果遍历到的节点不存在一条转移为 那么就新建一个为 的转移连接 。
- 如果访问到了 ,那么就令 ,回到第一步。
- 如果在访问时遇到了一个状态有为 的转移,那么令这个状态为 ,这个转移到达的状态为 。‘
- 如果有 ,那么令 ,,回到第一步。
- 新建一个状态 ,把 的所有信息(包括 和所有的出边),,令 。
- 将 以及 的一堆父亲中,所有指向 的边指向 以替代。
- 停止遍历, 然后回到第一步。
正确性证明
考虑在一个字符串的末尾添加一个字符,那么显然这个字符可以与前面的所有的后缀连接在一起组成新的子串。
对于新产生的子串有两种可能:新出现的和没有出现的。
为了添加这些东西,显然我们需要遍历所有的后缀,也就是访问 因为 的定义就是在这个等价类中不断的删除最开始的字符得到的新等价类。
因为 的加入使原本的字符串新加入了位置,所以要想让原串加入一个 之后的 不一样只能是在前面的子串中出现了新串的后缀。
因为 的定义是 所在的等价类中最短的元素删除头所得到,那么我们需要找到的就是新串的后缀在前面原串中作为子串出现的信息,因为只有这样 才会因为新元素的加入而改变。
显然根据 的定义, 指向的应该是原串中与新串的后缀相同的最长的子串的等价类的对应的状态。
因为我们通过 访问到的等价类内最长的元素是所在等价类中最短的字符串删除头,所以显然 指向的等价类中最长的字串是现在的等价类中最短的子串的子串。
而因为在同一个等价类中,较短的字符串一定是较短字符串的子串,所以这个等价类中的所有字符串都是原串的后缀。
此时有两种情况,如果这个等价类没有转移为 ,那么就直接添加就行了,然后继续访问后缀。
如果现在访问到的等价类中有 的转移,那么就一个现在所在的等价类 的字符串在头添加了 之后到达的等价类的 中有的串有与后缀相同的部分。
接下来有两种情况,如果等价类 中最长的字符串都是新串的后缀,那么显然整个 的 都会因为新的加入而改变,直接把 设置为 就行了。
如果满足上面的情况,那么需要满足 的最长的字符串在末尾添加了 之后就是 这个等价类中所拥有的最长的字符串,也就是 。
对于另一种情况,也就是等价类 中有一部分的字符串是新串的后缀而有一部分不是,所以就考虑把现在的等价类分割成为两个部分,一个部分是后缀而另外一个则不是。
把上面的操作放在 的视角看也就是有的 改变了而有的没有改变,把没有改变的字符串放在原处而新建出改变的等价类。
因为 所需要指向的是 真包含自己的 的最长的后缀所属于的等价类,所以限显然 也就是新建的节点。
因为我们取出的一部分字串就是满足等价类 中最长的字符串在末尾添加了字符 时候在 中最长,所以 。
因为等价类 的 就是在等价类 的 的基础上新添加了一个位置,所以显然根据引理 可以得到 。
因为等价类中最有的字符串 是的一大堆祖先的等价类中的字串,也就是后缀所以所有的祖先的 都会增加一个位置,所以原本指向 的节点就都应该指向 了。
模拟
如果你还是不明白,那么就去模拟吧!
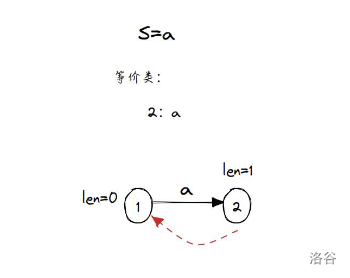
从上图到下图是第 种情况, 直接结束了。

从上图到下图是第 种情况,不断通过红边相会一直走到 都没有遇到为 的出边。

从上图到下图是第 种情况,在访问到 的时候遇到了有为 的出边,它指向了 。
这时 ,因为 或者说 所以新建了 号节点 作为新的节点。
然后 号节点复制了 号节点的出边,然后把 号节点和 号节点的 设置为了 。
从 开始访问通过红边访问,没有遇到指向 的值为 的边,所以不需要改变。
把 的红边设置为了 ,把 原本指向 的边改变到了 。
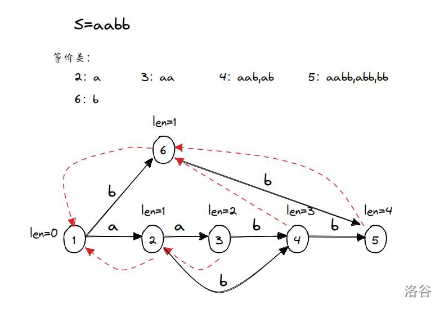
从上图到下图是第 种情况,在访问到 的时候遇到了一个为 的出边指向 。
此时 ,因为 或者说 所以直接把 设置为 就可以了。

在下面再放两张图,可以自己模拟一下:
- https://cdn.luogu.com.cn/upload/image_hosting/5ag5mc15.png
- https://cdn.luogu.com.cn/upload/image_hosting/aqm2i07p.png
{kind=link}
{kind=link}
实现
考虑对于每一个节点,类似于字典树的开一个长度为 的数组记录出边。
对于遇到的操作,直接模拟即可。
struct NODE{int to[26],len,link;NODE(){memset(to,0,sizeof(to));len=0;}}sam[N<<1];
int las=1,tot=1,n;
char a[N];
void add(int c){
int p=las;int np=las=++tot;sam[np].len=sam[p].len+1;
for(;p&&!sam[p].to[c];p=sam[p].link) sam[p].to[c]=np;
if(!p){sam[np].link=1;return;}
int q=sam[p].to[c];
if(sam[q].len==sam[p].len+1){sam[np].link=q;return;}
int nq=++tot;sam[nq]=sam[q];
sam[nq].len=sam[p].len+1,sam[q].link=sam[np].link=nq;
for(;p&&sam[p].to[c]==q;p=sam[p].link) sam[p].to[c]=nq;
}
时间复杂度分析
对于 SAM 的时间复杂度分析,我们都认为 对时间复杂度造成的影响为常数。
如果使用 map 存边那么时间复杂度为 ,空间复杂度为 。
如果使用直接开一个大小可以存储 中所有字符的数组存边,那么时间复杂度为 ,空间复杂度为 。
另外,请一定不要使用 unordered_map 因为可以用 SAM 解决的问题一般都要卡 unordered_map。
对于 SAM 的建立,有一些操作并不能明显的看出是线性的,考虑在下面分析一下。
但是在进行针对性的分析之前,我们需要先证明 SAM 的转状态和转移的个数都是线性的。
状态数
对于一个长度为 的字符串,其 SAM 的状态数不超过 。
其实这个算法的实现本身也可以证明这个结论,因为每一个操作我们都只会新建 个节点而且第 步和第 步都只会新增一个节点。
同时,因为 SAM 的每一个状态都对应这一个 ,所以我们在同时也证明了一个长度为 的字符串的等价类和不同的 不会超过 个。
转移数
对于一个长度为 的字符串,其 SAM 的转移数不超过 。
证明:
对于这个上界,感性理解发现可以通过类似于 的字符串产生,因为这样每一次都会新建节点然后复制一遍。
容易发现这是的转移数量为 ,
至于陈立杰高级的证明方法我是完全没有看懂,个人认为过于的意识流了一点。笔者打算去阅读一下国家集训队的论文,然后再回来填坑。
情况 1
对于从 开始向前遍历,为所有没有为 出边的节点添加出边。
证明:
因为 SAM 中最多有的状态数是 的,而且每一个节点最多只会被添加一个为 的出边,所以为 的出边的个数必定是 的。
因为遍历操作每访问一次都会加一个为 的出边,所以先让这个操作的时间复杂度为 。
情况 2
在 复制到 的过程。
证明:
因为复制的会使出边的数量增加,而 SAM 的出边的个数又是 的,所以这个操作也是 的。
情况 3
把 复制到 之后去遍历 的祖先。
证明:
我们定义一个等价类 的最长的字符串为 ,显然这是一个添加了 之后的字符串的后缀。
这是如果 所在的位置与 之间的 的数量大于 ,那么 将会被 的 指向。
而容易理解这个位置是会不断递减的,换而言之 的位置是单调的。
综上所述,这个循环不会被执行超过 次。
应用
求解字串出现次数
容易理解对于一个等价类里的字串,其出现次数就是 的大小。
有一个误区,那就是如果有 连接,其实 的大小差距不一定是 。
只有 的 一定是,所以应该在 DP 的只把 的大小记录成 ,转移的时候这个节点的大小就是其子节点的大小的和。
另外,一个等价类中最长的字符串的长度就是 。
最小表示
把求解的字符串重复一遍,建立 SAM。
从源点开始贪心的走 步,最后得到的就是最小表示。
不同子串个数
容易想到,对于新添加的一个 ,其贡献就是 ,也就是 。
之所以如果新添加一个点不计算贡献,是因为其贡献在上一次重复的时候已经计算过了,新加入点的本质是把以前出现的串分类。
第 小字串
考虑建出 SAM 之后预处理出经过每一个点的字串数量,然后类似于线段树二分的操作,直接向下找就行了。
具体的,一个点包含的字串个数为 的大小加上其所有出边包含的。
但是有一个问题,在求解出现字串次数时不能直接 dfs 然后回溯,这样会导致有些节点儿子的贡献没有转移结束就被父亲多次调用,正确的方法应该是对这个 DAG 进行拓扑排序。
